
မင်္ဂလာပါ။
ကျွန်တော်ကတော့ Spiceworks Myanmar မှာ Backend Developer အနေနဲ့ တာဝန်ယူလုပ်ကိုင်နေတဲ့ သုတယာမိုး ဖြစ်ပါတယ်။ ဒီတစ်ခေါက်မှာတော့ regular expression အကြောင်းကို ဝေမျှပေးချင်ပါတယ်။
Regular Expression ဆိုတာကတော့ strings တစ်ခုမှာ မိမိလိုချင်တဲ့ sequence of characters တွေကို pattern တွေအဖြစ်နဲ့ရေးပြီး အသုံးပြုလို့ရတဲ့ နည်းပညာတစ်ခုပဲဖြစ်ပါတယ်။ Regular Expression ဟာ programming language တိုင်းမှာ ပါဝင်ပြီး အတိုကောက်အနေနဲ့ regex လို့လည်း ခေါ်ကြပါတယ်။ Regex ကို strings တစ်ခုမှာ မိမိလိုချင်တဲ့ characters တွေကို ရှာချင်တဲ့အခါ input validation စစ်တဲ့အခါမျိုးတွေမှာ အသုံးပြုကြပါတယ်။ ပထမဆုံးအနေနဲ့ Alphanumeric Characters နှင့် Special Characters တွေက ဘာတွေလဲဆိုတာကို ဝေမျှချင်ပါတယ်။ Alphanumeric Characters ကတော့ a ကနေ z အထိ၊ A ကနေ Z အထိ၊ 0 ကနေ 9 အထိ နဲ့ _ (underscore) တို့ပဲဖြစ်ပါတယ်။ Special Characters တွေကတော့ [!@#%^&*()+-=[]{}|;’:”,./?~`] တို့ပဲဖြစ်ပါတယ်။ Special Characters ထဲမှာ underscore (_) မပါဝင်တာကို သတိပြုရမှာဖြစ်ပါတယ်။ Regular Expression pattern တွေကိုတော့ /…/ (slash) နှစ်ခုကြားမှာ ရေးပေးရမှာဖြစ်ပါတယ်။ Aplanumeric Characters တွေကိုတော့ /abc/ ယခုကဲ့သို့ရေးနိုင်ပြီး Special Characters တွေကိုတော့ /\.\$/ back slash (\) အရှေ့ကခံပြီးရေးပေးရမှာ ဖြစ်ပါတယ်။ Regex ကို အပိုင်း(၅) ပိုင်းခွဲပြီး လေ့လာသွားကြပါမယ်။
အပိုင်း(၁) ကတော့ Character Classes အကြောင်း ဖြစ်ပါတယ်။
. (Any character except for new line)
. (Dot) ကတော့ characters အကုန်လုံးကို လိုချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။
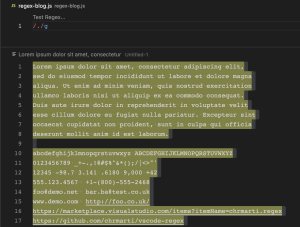
\w (Any word characters)
\w ကတော့ Alphanumeric Characters လိုချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။
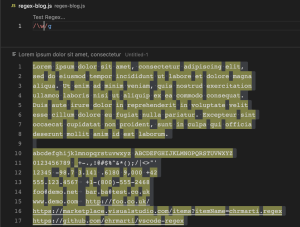
\d (Digit characters)
\d ကတော့ 0,1,2,3,4,5,6,7,8,9 အစရှိတဲ့ digit characters လိုချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။
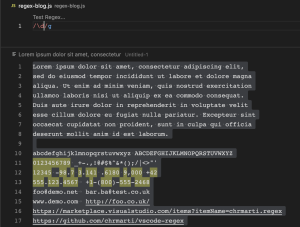
\s (Whitespace character)
\s ကတော့ whitespace character( ) ကို လိုချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခုဖြစ်ပါတယ်။
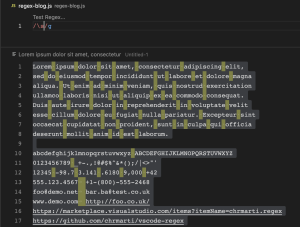
\W (Not word characters)
\W ကတော့ \w နဲ့ ပြောင်းပြန်ဖြစ်ပြီး alphanumeric characters မဟုတ်တဲ့ အခြား characters တွေကို လိုချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။
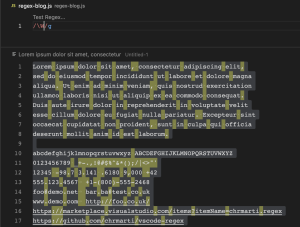
\D (Not digit characters)
\D ကတော့ \d နဲ့ ပြောင်းပြန်ဖြစ်ပြီး digit characters (0 to 9) မဟုတ်တဲ့ အခြား characters တွေကို လိုချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။
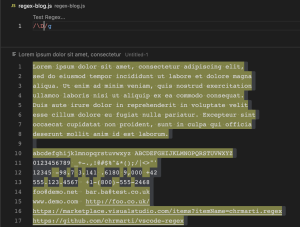
\S (Not whitespace character)
\S ကတော့ \s နဲ့ ပြောင်းပြန်ဖြစ်ပြီး Whitespace Character ( ) မဟုတ်တဲ့ အခြား characters တွေကို လိုချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။
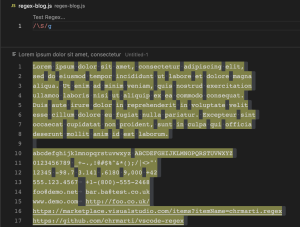
[abc] (Character set)
/[abc]/ လေးထောင့်ကွင်းအတွင်းရေးတဲ့ regex pattern ကတော့ Characters တွေအများကြီးတွေမှ မိမိလိုချင်တဲ့ character အချို့ကိုပဲ match ဖြစ်စေချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။
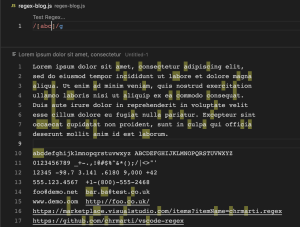
[^abc] (Not character set)
/[^abc]/ regex pattern ကတော့ လေးထောင့်ကွင်းထဲက character တွေမဟုတ်တဲ့ အခြား characters တွေကို လိုချင်တဲ့အခါမှာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။
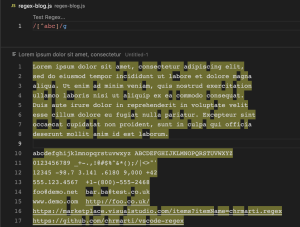
[a-zA-Z0-9] (character between a to z, A to Z & 0 to 9)
/[a-z]/ hyphen(-) ခံပြီးရေးတဲ့ regex pattern ကတော့ abcdef ဆိုပြီး အရှည်ရေးနေစရာမလိုဘဲ မိမိလိုချင်တဲ့ character အပိုင်းအခြားကို [a-f] hyphen (-) ခံကာ အသုံးပြုတဲ့ pattern တစ်ခု ဖြစ်ပါတယ်။ /[a-f]/ ဆိုရင် a ကနေ့ f အထိ characters (abcdef) ၊ [1-5] ဆိုရင် 1 ကနေ 5 အထိ characters (1,2,3,4,5) အစရှိသဖြင့် -(hyphen) ခံပြီး ရေးပေးရမှာဖြစ်ပါတယ်။
အပိုင်း(၂) ကတော့ Quantifiers & Alternation အကြောင်းဖြစ်ပါတယ်။
a* (0 or more)
* ကတော့ သုည (သို့) တစ်ခုနှင့်တစ်ခုထက်ပို ဆိုတဲ့အဓိပ္ပါယ် ဖြစ်ပါတယ်။ ca* ဆိုတဲ့ regex pattern မှာဆိုရင် c ရဲ့ အနောက်မှာ a ပါတဲ့ sequence of characters တွေလည်း match ဖြစ်တယ်၊ မပါတဲ့ sequence of characters တွေကလည်း match ဖြစ်တယ်လို့ဆိုလိုတာ ဖြစ်ပါတယ်။
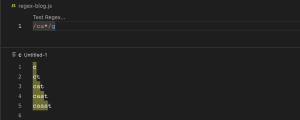
a+ (1 or more)
+ ကတော့ တစ်ခု (သို့) တစ်ခုထက်ပို ဆိုတဲ့အဓိပ္ပါယ် ဖြစ်ပါတယ်။ ca+ ဆိုတဲ့ regex pattern မှာဆိုရင် c ရဲ့ အနောက်မှာ a တစ်ခု အနည်းဆုံးပါဝင်တဲ့ စကားစုတွေသာ match ဖြစ်တယ်လို့ဆိုလိုတာ ဖြစ်ပါတယ်။
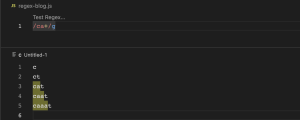
a? (0 or 1)
? ကတော့ သုည (သို့) တစ်ခု ဆိုတဲ့အဓိပ္ပါယ် ဖြစ်ပါတယ်။ ca? ဆိုတဲ့ regex pattern မှာဆိုရင် c ရဲ့ အနောက်မှာ a တစ်ခု (သို့) a မပါတဲ့ စကားစု တွေ match ဖြစ်တယ်လို့ဆိုလိုတာ ဖြစ်ပါတယ်။
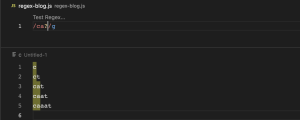
a{3} (Exactly 3)
{3} ကတော့ သုံးခု အတိအကျလို့ ဆိုလိုတာဖြစ်ပါတယ်။ ca{3} ဆိုတဲ့ regex pattern မှာဆိုရင် c ရဲ့ အနောက်မှာ a သုံးခု အတိအကျပါတဲ့ စကားစုတွေ match ဖြစ်တယ်လို့ဆိုလိုတာ ဖြစ်ပါတယ်။
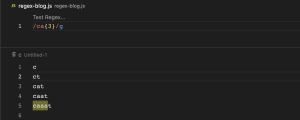
a{3,} (3 or more)
{3,} ကတော့ သုံးခု (သို့) သုံးခုနှင့်အထက်လို့ ဆိုလိုတာဖြစ်ပါတယ်။ ca{3,} ဆိုတဲ့ regex pattern မှာဆိုရင် c ရဲ့ အနောက်မှာ a သုံးခု (သို့) သုံးခုနှင့်အထက် ပါတဲ့ စကားစု တွေ match ဖြစ်တယ်လို့ဆိုလိုတာ ဖြစ်ပါတယ်။
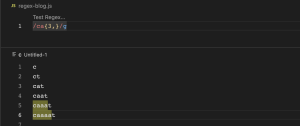
a{1,3} (between 1 and 3}
{1,3) ကတော့ တစ်ခု နှင့် သုံးခုကြားလို့ ဆိုလိုတာဖြစ်ပါတယ်။ ca{3,} ဆိုတဲ့ regex pattern မှာဆိုရင် c ရဲ့ အနောက်မှာ a တစ်ခုနှင့် သုံးခုကြားပါတဲ့ စကားစုတွေ match ဖြစ်တယ်လို့ဆိုလိုတာ ဖြစ်ပါတယ်။
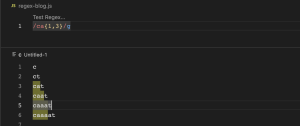
ab|cd|ef (alternation)
ab|cd|ef မှာပါတဲ့ | ကတော့ (or) ဆိုတဲ့ အဓိပ္ပါယ် ဖြစ်ပါတယ်။ ab (သို့) cd (သို့) ef ပါတဲ့ စကားစု တွေ match ဖြစ်တယ်လို့ဆိုလိုတာ ဖြစ်ပါတယ်။
အပိုင်း(၃) ကတော့ Anchors & Boundaries အကြောင်းဖြစ်ပါတယ်။
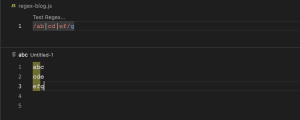
/^/ (start of the string)
/^/ ကတော့ စာကြောင်းတွေအများကြီးထဲမှ မိမိအစပြုစေချင်တဲ့ character တွေပါဝင်တဲ့ စာကြောင်းကို ရယူလိုတဲ့အခါမျိုးမှာ အသုံးပြုတဲ့ pattern ဖြစ်ပါတယ်။ /^Wh(.)*/ regex pattern ဆိုရင် Wh နဲ့ စတဲ့ စာကြောင်းတွေသည် match ဖြစ်တယ်လို့ ဆိုလိုတာဖြစ်ပါတယ်။
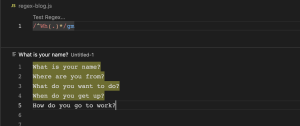
/$/ (end of the string)
/^/ ကတော့ စာကြောင်းတွေအများကြီးထဲမှ မိမိအဆုံးသတ်စေချင်တဲ့ character တွေပါဝင်တဲ့ စာကြောင်းကို ရယူလိုတဲ့အခါမျိုးမှာ အသုံးပြုတဲ့ pattern ဖြစ်ပါတယ်။ /(.)*big.$/ regex pattern ဆိုရင် big. နဲ့ ဆုံးတဲ့ စာကြောင်းတွေသည် match ဖြစ်တယ်လို့ဆိုလိုတာ ဖြစ်ပါတယ်။
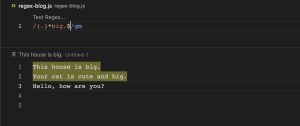
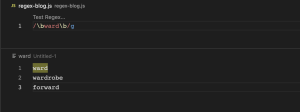
\b (word boundary)
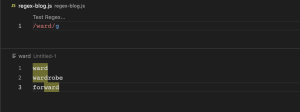
\b ကတော့ word boundary ဆိုတဲ့ အတိုင်း စကားလုံးတွေကို ဘောင်ခတ်လိုက်ခြင်းပဲဖြစ်ပါတယ်။ /ward/ regex pattern ဆိုရင် ward က string တစ်ခုရဲ့ ဘယ်နေရာမှာမဆို ပါနေရင် match ဖြစ်တယ်လို့ဆိုလိုပါတယ်။ ဥပမာ wardrobe, forward. \/bward\b/ regex pattern မှာကတော့ ward ဆိုတဲ့ စကားစုအတိုင်း (only ward) မှသာ match ဖြစ်တယ်လို့ဆိုလိုပါတယ်။
အပိုင်း(၄) ကတော့ groups & lookaround အကြောင်းဖြစ်ပါတယ်။
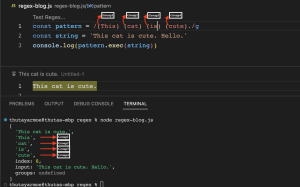
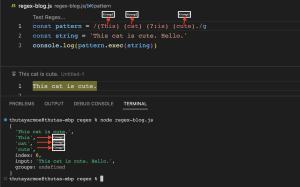
(abc) (Capturing Group)
(abc) regex pattern ကတော့ လက်သည်းကွင်းအတွင်းရေးထားတဲ့ character တွေကို group အဖြစ်သတ်မှတ်ပေးတဲ့ pattern ဖြစ်ပါတယ်။ /(This)(cat)(is)(cute)./ regex pattern မှာဆိုရင် (This) သည် group1, (cat) သည် group 2, (is) သည် group 3 နှင့် (cute) သည် group4 ဆိုပြီး capturing group (၄)ခု ပါဝင်မှာဖြစ်ပါတယ်။
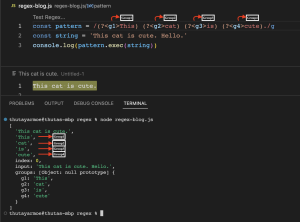
(?<<name>>abc) (Named capturing group)
(?<<name>>abc) Capturing Group တွေကို name ပေးချင်ပါက (?<<custom_name>>abc) ဆိုပြီး ရေးပေးရမှာဖြစ်ပါတယ်။ <> ကပုံပါတိုင်းတစ်ခုသာရေးရန်လိုအပ်ပါတယ်။ Editor မှာက ထိုသင်္ကေတတွေသည် နှစ်ခါရေးမှသာ ပေါ်တဲ့အတွက် ၂ခါရေးထားခြင်းဖြစ်ပါတယ်။
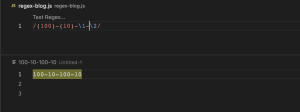
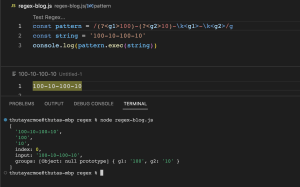
\1\2 (Back reference)
\1\2 ကတော့ အရှေ့မှာရှိတဲ့ capturing group() ရဲ့ pattern ကနေ စစ်လိုက်လို့ match ဖြစ်တဲ့ characters တွေနဲ့ အခြားနောက်တစ်နေရာမှာ ဆက်ပြီးတော့ match ဖြစ်မဖြစ် စစ်ချင်တဲ့အခါမျိုးမှာ နှစ်ခေါက်မရေးဘဲနဲ့ Capturing group ဖွဲ့ပြီး ထို group ကိုပြန်ခေါ်သုံးတဲ့ pattern ဖြစ်ပါတယ်။ /(100)—(10)-\1-\2/ regex pattern မှာဆိုရင် \1 က group1 ဖြစ်တဲ့ (100) ကိုကိုယ်စားပြုပြီး \2 ကတော့ group2 ဖြစ်တဲ့ (10) ကိုကိုယ်စားပြုတာဖြစ်ပါတယ်။ ထို့အတွက်ကြောင့် အခုလိုပုံစံမျိုး /(100)—(10)-100-10/ pattern ကို ၂ခါပြန်ရေးနေစရာမလိုဘဲ \1\2 ဆိုပြီး အစားထိုးအသုံးပြုနိုင်မှာဖြစ်ပါတယ်။ အကယ်၍ named capturing group တွေကို group နာမည်ဖြင့်ခေါ်သုံးချင်ပါက /(?100)-(?10)-\k<<g1>>-\k<<g2>>/ ယခုကဲ့သို့ \1\2 အစား \k နောက်မှာ မိမိပေးထားတဲ့ group name ကို ရေးပေးရမှာဖြစ်ပါတယ်။
(?:abc) (Non capturing group)
(?:abc) regex pattern ကတော့ capturing group ဖွင့်လိုက်ပေမယ့် ထို group ကို မသုံးချင်ဘဲ skip လုပ်စေချင်တဲ့အခါမျိုးမှာ အသုံးပြုတဲ့ pattern ဖြစ်ပါတယ်။
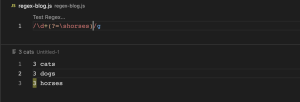
(?=abc) (Positive lookahead)
(?=abc) regex pattern ကတော့ 3 cats, 3 dogs, 3 horses ဆိုတဲ့ string တစ်ခု ရှိတယ်ဆိုပါစို့။ အဲ့အထဲကမှ horses ရဲ့အရှေ့က 3 ဆိုတဲ့ character တွေကို လိုချင်တဲ့အခါမျိုးမှာ အသုံးပြုတဲ့ pattern ဖြစ်ပါတယ်။
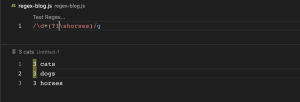
(?!abc) (Negative lookahead)
(?!abc) regex pattern ကတော့ 3 cats, 3 dogs, 3 horses ဆိုတဲ့ string တစ်ခု ရှိတယ်ဆိုပါစို့။ အဲ့အထဲကမှ horses ရဲ့အရှေ့က 3ကလွဲပြီး cats နဲ့ dogs အရှေ့က 3 character တွေကို လိုချင်တဲ့အခါမျိုးမှာ အသုံးပြုတဲ့ pattern ဖြစ်ပါတယ်။
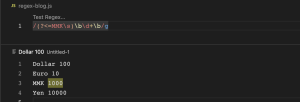
(?<=abc) (Positive lookbehind)
(?<=abc) regex pattern ကတော့ Dollar 100, Euro 10, MMK 1000, Yen 10000 ဆိုတဲ့ string တစ်ခု ရှိတယ်ဆိုပါစို့။ အဲ့အထဲကမှ MMK ဆိုတဲ့ အနောက်မှာရှိတဲ့ digit characters တွေကို လိုချင်တဲ့အခါမျိုးမှာ အသုံးပြုတဲ့ pattern ဖြစ်ပါတယ်။
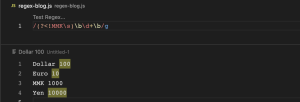
(?<!abc) (Negative lookbehind)
(?<!abc) regex pattern ကတော့ Dollar 100, Euro 10, MMK 1000, Yen 10000 ဆိုတဲ့ string တစ်ခု ရှိတယ်ဆိုပါစို့။ အဲ့အထဲကမှ MMK ဆိုတဲ့ အနောက်မှာရှိတဲ့ digit characters ကလွဲပြီး Dollar, Euro, Yen တိုရဲ့ အနောက်က digit characters တွေကို လိုချင်တဲ့အခါမျိုးမှာ အသုံးပြုတဲ့ pattern ဖြစ်ပါတယ်။
အပိုင်း(၅) ကတော့ Flags အကြောင်းဖြစ်ပါတယ်။
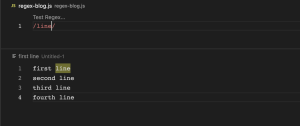
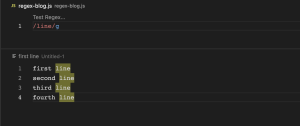
(/./g)(global)
Regular Expression မှာ (/./g) g flag သည် အများဆုံး အသုံးပြုတဲ့ flag ဖြစ်ပါတယ်။ အကယ်၍ g flag သာမပါဝင်ပါက မိမိရေးထားတဲ့ pattern နဲ့ ပထမဆုံး match ဖြစ်တဲ့ စကားစုတွေကိုပဲ match ဖြစ်တယ်လို့ ယူဆမှာဖြစ်ပါတယ်။
/./i (Case Insensitive)
i flag ကတော့ စကားလုံး အကြီး (uppercase) ဖြစ်ဖြစ်၊ အသေး(lowercase) ဖြစ်ဖြစ် လက်ခံတယ်လို့ ဆိုလိုတဲ့ flag ဖြစ်ပါတယ်။ /the/i regex pattern ဆိုရင် the သည် အကြီး စကားလုံးဖြစ်ဖြစ် အသေးစကားလုံးဖြစ်ဖြစ် match ဖြစ်တယ်လို့ဆိုလိုပါတယ်။
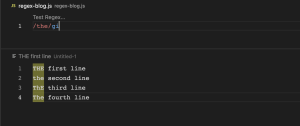
/^.$/m (multiline)
M flag ကိုတော့ ^(beginning) or $(end) ပါဝင်တဲ့ regex pattern တွေမှာ အသုံးပြုပါတယ်။ /^It(.)*/m regex pattern ဆိုရင် It နဲ့ စတဲ့ စာကြောင်းတွေသည် match ဖြစ်တယ်လို့ ဆိုလိုတာဖြစ်ပါတယ်။ အကယ်၍ m flag သာမပါပါက ပထမဆုံး match ဖြစ်တဲ့ စာကြောင်းကိုပဲ လက်ခံမယ်လို့ ယူဆသွားမှာဖြစ်ပါတယ်။
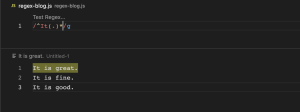
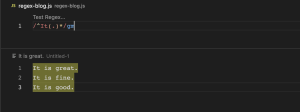
အခုဆိုရင်တော့ Regular Expression အကြောင်းကို နားလည်သွားမယ်လို့ ထင်ပါတယ်။ Regular Expression အကြောင်းကို ပိုမိုလေ့လာချင်ပါက
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp
https://regexr.com
https://www.rexegg.com
အထက်ပါလင့်ခ်များမှတစ်ဆင့် လေ့လာနိုင်ပါတယ်။ အဆုံးထိဖတ်ရှုပေးတဲ့အတွက် ကျေးဇူးတင်ပါတယ် ခင်ဗျ။
